
Lloyd’s Core Data Record: The key to unlocking digital
16 April, 2021
On 11 March 2021, Lloyd’s released the first iteration of the “Core Data Record” (CDR). In this blog, we provide an overview of the CDR, how it works, and our views on the opportunity, and where there might be challenges.
CDR ‘too long didn’t read’ version
What is it? Lloyd’s Core Data Record is a standard data collection template for policy data intended to work across the Lloyd’s and London Market.
How does it work? Insurers/brokers will provide critical transaction data at the point of bind for a policy. This data will then be stored and made available to insurers and brokers throughout the policy lifecycle (e.g. during claims settlement).
What happens next? Lloyd’s are currently consulting with the market on the first iteration of the CDR – this is being developed for Open Market North American Property. There is no official launch timeline yet but an update from Lloyd’s is expected at the end of March.
(Update: on April 6 Lloyd’s released a second iteration of the CDR. The template can be viewed here.)
What is the Core Data Record (CDR)
The Core Data Record (CDR) is a template that will collect critical transactional data during the placement process. It will collect data such as policyholder details (name, address), insurance contract details (currency, start & end period, premium), coverage details (peril, sum insured), and participation line details (lead/follow indicator, signed percentage line). The CDR will be made available to all the relevant stakeholders (e.g. insurers, brokers) of a particular policy for the duration of a policy lifecycle (e.g. placement through to claims).
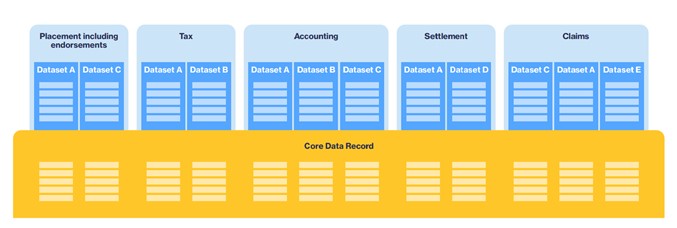
Figure 1 Illustration of the Core Data Record. Source: Blueprint Two.
The CDR will vary by COB – data fields relevant for some policies may be irrelevant for others (e.g. property policies require a physical address for the insured address where liability policies don’t). For the first CDR iteration, Lloyd’s is using Open Market North American Property as a pilot but will expand to other COBs and subsequently Delegated Authority business.
To reduce the data input burden during the placement process, the CDR will be made up of two types of data.
1. Placement processing data – data that must be inputted during the placement process
2. Derived data – fields that can be derived/calculated without the need for manual input
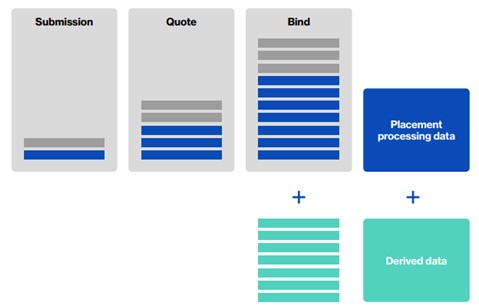
Figure 2 Types of data used to form the Core Data Record. Source: Blueprint Two.
For North American Property risks, Lloyd’s have identified that of the maximum number of data fields required (105), 34 must be completed at bind and the remaining majority of 71 can be derived data fields i.e. calculated using the information provided from the original 34 fields.
Why create the CDR?
The CDR is ultimately intended to aid digitisation in Lloyd’s. It will collect standardised, high quality, and “right-first-time” data upfront which will, in turn, enable downstream digital processing and reporting.
For example, during the claims eFNOL process, the CDR will support the automatic retrieval, validation, and matching of policy details. This might include ensuring the location of the loss is covered by the policy, validating that a premium has been paid, and confirming that the peril that caused the loss is covered by the policy.
What happens next?
The first iteration of the CDR has been developed with input from ACORD, brokers, and insurers.
“ACORD is committed to enabling digitisation at Lloyd’s and throughout the global insurance ecosystem. The development of the Core Data Record, based on ACORD Standards, will ensure that market participants are able to leverage their existing systems and taxonomies to provide data in a consistent and coherent way. This will enable Lloyd’s stakeholders to maximise the value derived from their data, increase flexibility and adaptability, and capture efficiencies made possible only by digital transformation. ACORD Standards reduce the frictional costs of data exchange, and there are significant network effects. Standards allow market participants to more easily integrate with the Lloyd’s ecosystem, deploy state-of-the-market solutions, and connect with new trading partners, platforms, and geographies.”
Bill Pieroni, President & CEO of ACORD, the standards-setting body for the global insurance industry
It has been released to the market for public comment and the next progress updated is expected at the end of March.
(Update: on April 6 Lloyd’s released a second iteration of the CDR. The template can be viewed here.)
The Oxbow Partners View
The Core Data Record is essentially the key to unlocking digitisation. It will create a single, digital version of the truth for Lloyd’s policies and in doing so will enable digital processing, automation, and even STP at later stages of the value chain.
The CDR is a big step in the right direction for the market. Access to reliable data is a significant challenge for market participants when it comes to digitisation. In Lloyd’s paper is still seen as the primary repository for fact, although this is swiftly changing – in part driven by the pandemic and the need to work remotely. CDR will certainly be a key enabler of driving this change.
However, the CDR still doesn’t cover off one significant area and that is pre-bind submissions. Many of our clients see a significant opportunity in digitising submission to both increase efficiency as well as improving the quality of risk selection and underwriting. At this stage, CDR does not resolve this. Having said that you have to start somewhere and submissions are a messy business in data terms.
There are several questions Lloyd’s will no doubt be tackling in the coming months to ensure the CDR is a success. For example: how do you ensure full usage across the market? How will the standards be decided and how can we avoid a “long list” of standards which includes everyone’s requirements rather than prioritising the minimum amount?
Get market insights straight to your inbox


